Documentation
If you just want to start using Ajira then you should first read our getting started guide, which should teach you to set up the environment and start to use the framework.
The next step would be to read our tutorial, where we illustrate a small example application step-by-step. This should explain you the main ideas behind Ajira.
Finally, if you are interested on what happens behind the curtains, then you should read our description of the architecture of Ajira, and the philosophy that drives its development.
Getting started
Download and compile the code
A simple clone with:
git clone https://github.com/jrbn/ajira.git
should do the job. After this, you must compile the codebase using the ant file in the main directory. Just type:
ant
and the script will create the jars with all the program. These
files should be labeled with ajira-XXX.jar
and ajira-webapps-XXX.jar. The first jar contains the
actual program, while the second contains the .jsp files for the web
interface. Normally you need both, but if you decide not to use the
web interface than you can skip the second one.
As almost all java programs, Ajira depens on external libraries. These are contained in the lib/ directory. If you want to use the program, remember to include also all the jars in this directory in your classpath, otherwise you will have a problem. For convienency, we added a script to copy all these jars in a "fat" jar. If you want it, just type:
ant fat-jar
and the program will create a ajira-fat-XXX.jar jar
file.
Launch on a single node
For a quick launch, you can try the WordCount example that we added in the nl.vu.cs.ajira.examples package (in the tutorial we will use this example to explain how the program works). This program accepts in input a directory with a number of text files with some generic text (the files can be either compressed or not) and returns in output a list of words with the number of occurrences that they appear on the text.
To launch the program, just type:
java -cp ajira-fat-XXX.jar:conf/ nl.vu.cs.ajira.examples.WordCount <inputdir> <outputdir>
where inputdir is the directory in input and outputdir the directory which will contain the results of the program (note that in this example the directory conf/ is added to set a default logging level to info, otherwise all logging messages would be printed in output).
Launch on multiple nodes
TODO
Tutorial
Overview
An Ajira program consists of a list of actions to be executed in a sequence.
Each of these actions receives some data in input and produces some data in output. The data in output will become the input of the action until the sequence is finished. At this point the program is terminated.
A user who wants that wants to write a program in Ajira only needs to define such sequence of actions, and to implement the actions that are not already provided by the framework. Once this is done, Ajira will take care of execution of the program in the most efficient way, parallelizing and distributing it across the nodes.
In Ajira, data is always expressed as a number of tuples, of variable length and type. The elements of the tuples can be numbers (byte, int, or long), strings, booleans or similar simple types. Because of this, actions are essentially computational units that transforms tuples in other tuples.
For example, suppose that we want to sample a number of records from a set of files, group them by a given criteria and write the results on a number of files. To achieve this simple task, four actions are necessary: 1) Read the data from the files; 2) sample the input; 3) group it; 4) write the results on disk.Such program can be written with Ajira with just a few lines.
As you can see, there are quite a number of similarities between Ajira and MapReduce, but there is also an important difference. In MapReduce, only two types of actions are possible: a map and reduce. In Ajira, you are not bound by a two-phases computation, but you can construct a chain of computation as complex as you like.
This allows the programmer a much greater flexibility in implementing complex programs. For example, let's slightly change our previous example, adding the operation of removing possible duplicates in the input before executing the sampling. Performing this new task in a single MapReduce job would be rather tricky, since we are required to perform multiple sortings (one to clean the duplicates and one to group the sample).
However, this is not the case of Ajira, where multiple sorting phases can be stacked up in the same sequence of actions. To better show this, we draw in Figure 1 a sketch of how a MapReduce program would look like, and how the same operations would be written in Ajira.
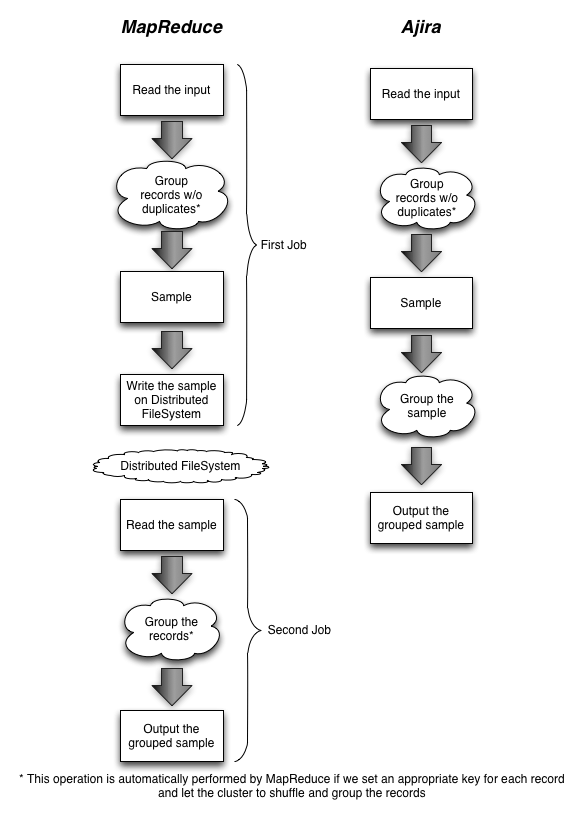
Figure 1: Execution of a sample program using MapReduce and Ajira.
The execution of an Ajira program is sequential, since the actions are executed one after the other. However, in reality the framework tries to parallelize the execution and even to distribute it across several peers in a (semi)transparent way. For example, consider the standard action ReadFromFiles, which is provided by the framework and which task is to read the content on some files and feed it to the next actions in the list. Here, the user only specifies at what point this action should be executed in the sequence (e.g. ReadFromFiles->Sample->WriteToFiles), but nothing more.
When Ajira will physically execute this action, it will first create a number of concurrent "chains" depending on the input size. For example, if there are two files, fileA.txt and fileB.txt, Ajira create two concurrent chains of actions where one will process the content of fileA.txt while the other will process the content of fileB.txt.
If the user needs that the flow of tuples in one sequence must be converged to one or multiple processors (for example to apply some aggregating operations), then Ajira provides a number of special actions, like CollectToNode or PartitionToNodes to make sure that all the tuples that are processed in parallel are collected in one single point.
We will now take the classical MapReduce WordCount example, and show how we can rewrite it in Ajira.
Example: WordCount
The scope of this tutorial is to understand how a simple program that written using the Ajira framework works. To this end, let's take example program WordCount.java and start reading the code, to understand how it works.
The purpose of this program is to count the occurrences of words in a text files. After MapReduce, became a sort of Hello World for data intensive applications. The program receives in input a set of files and returns in output a number of pairs where the first element is a word that occurred at least once in the input collection and the second element the number of times that it occurred.
The program can be divided in two parts. The first, which is between lines 118 and 133, takes care of initializing the framework. In this phase, the framework can be customized by setting some parameters (in the example, N_PROC_THREADS indicates the number of concurrent threads that can perform the actual computation).
After the initialization is completed, the framework can be started with the command Ajira.startup(). Note that this code must be executed on all nodes that participate in the computation. After this function is executed, Ajira is running and waiting to receive a submission.
The function Ajira.amITheServer() is used to make sure that some code is executed only once and not on every instance of the program. In fact, this function will return true only on one node (actually the first that joins the computation). This means that the if in lines 116-150 will be executed only on one node and skipped on all the other instances.
Inside this if we set up the computation that will execute the WordCount program. This is done in the function createJob(). We report the content of the function below:
public static Job createJob(String inDir, String outDir)
throws ActionNotConfiguredException {
Job job = new Job();
ActionSequence actions = new ActionSequence();
// Read the input files
ActionConf action = ActionFactory.getActionConf(ReadFromFiles.class);
action.setParamString(ReadFromFiles.S_PATH, inDir);
actions.add(action);
// Count the words
actions.add(ActionFactory.getActionConf(CountWords.class));
// Groups the pairs
action = ActionFactory.getActionConf(GroupBy.class);
action.setParamStringArray(GroupBy.SA_TUPLE_FIELDS,
TString.class.getName(), TInt.class.getName());
action.setParamByteArray(GroupBy.IA_FIELDS_TO_GROUP, (byte) 0);
actions.add(action);
// Sum the counts
actions.add(ActionFactory.getActionConf(SumCounts.class));
// Write the results on files
action = ActionFactory.getActionConf(WriteToFiles.class);
action.setParamString(WriteToFiles.S_OUTPUT_DIR, outDir);
actions.add(action);
job.setActions(actions);
return job;
}
Here we define a list of actions that need to be executed in a sequence in order to implement the operations required by the program. The first action is called ReadFromFiles and is a standard action provided by the framework. Its task is to read the files in input and return their contents to the following actions. The content is returned as a number of tuples, where each tuple contains a line of the text files (in case, it is possible to set a custom reader that returns tuples with different structure or content).
The operation is done with the instructionActionConf action = ActionFactory.getActionConf(ReadFromFiles.class);which is used to retrieve an object that contains the configuration of the action. Depending on the action, such object will accept certain parameters instead of others. The second line,
action.setParamString(ReadFromFiles.S_PATH, inDir),
simply sets as the action parameter the directory to be read in
input.
The second action that needs to be executed is called CountWords and must be defined by the user. In the code it is defined in lines 38-54. For clarity we report it below.
public static class CountWords extends Action {
@Override
public void process(Tuple tuple, ActionContext context,
ActionOutput actionOutput) throws Exception {
TString iText = (TString) tuple.get(0);
String sText = iText.getValue();
if (sText != null && sText.length() > 0) {
String[] words = sText.split("\\s+");
for (String word : words) {
if (word.length() > 0) {
TString oWord = new TString(word);
actionOutput.output(oWord, new TInt(1));
}
}
}
}
}
The only method that the abstract action Action requires to implement is the method process(...). This method receives as input one tuple and produces in output one of more tuples. Note that here an action resembles very much the task of a Map in the MapReduce model since also here one tuple can generate zero or more other tuples (however, note that in our case an action can do much more than a map).
In fact, here the action CountWords does exactly the same task as the Map phase in the MapReduce version of this example: Split the input text in words, and for each of them output a new pair ("word", 1). This operation is done in the process(...) method of this action.
The third action is called GroupBy and is a standard action provided by the framework. The process method of this action will receive in input the output of the CountWords action and it will group it other tuples that will be passed to the following action. Once again, this action is needed to simulate exactly the computation that occurs in MapReduce: In fact, also there the output of the Map need to be grouped by the framework so that on each group a Reduce action could be applied.
This action needs some parameters. First we need to tell it exactly which type of tuples the action will receive in input. This is necessary for the sorting. In the example, each tuple is composed by a string (TString) and an integer (TInt). The second parameter (IA_FIELDS_TO_GROUP) is needed to indicate which fields of the tuple we should use to group the entire tuple. In our case we want the tuples being grouped by the word and therefore we set this parameter to the value 0.
The third action is the "reduce" of the MapReduce counterpart program. In our example this action is called SumCounts and is defined in lines 64-76.
public static class SumCounts extends Action {
@Override
public void process(Tuple tuple, ActionContext context,
ActionOutput actionOutput) throws Exception {
TString word = (TString) tuple.get(0);
TBag values = (TBag) tuple.get(1);
long sum = 0;
for (Tuple t : values) {
sum += ((TInt) t.get(0)).getValue();
}
actionOutput.output(word, new TLong(sum));
}
}
This action receives in input a tuple that contains first all the fields that were used as a key by the GroupBy action and as last field an instance of the class TBag that contains a collection of the tuples in each group. Exactly as it happens in MapReduce, this class sums the number 1 produces by the action CountWords and return these values in the output.
The last action in the chain is called WriteToFiles and is a standard action provided by the framework. The task of this action is to write the tuples in input on files. The output directory is indicated with the parameter S_OUTPUT_DIR.
Once the job is defined, the user can execute it launching the command Ajira.waitForCompletion(). Once the job is executed, it is possible to print out some statistics about the execution with the command Submission.printStatistics().
Great! Was everything clear? Once again, the scope of this tutorial was to simply make you familiar with the framework. As you could read from it, we only had to define the flow of actions necessary to perform our task. In this example, these actions mimic exactly the behaviour of MapReduce, since the two actions that are defined by the user can be mapped directly in the "map" and "reduce" functions of MapReduce.
In others, more advanced documents that you can find on this website, we will describe the framework in more detail, focusing on how the computation is physically carried on and on all actions that is possible to execute. We encourage you to read them, but first try out this example on your machine so that you can get a concrete feeling on how the framework works in practice.
System Architecture
An Ajira cluster is made by one or more Ajira instances that communicate to each others through the network. In Figure 2, we show a typical example of Ajira cluster. In the Figure, each Ajira instance consists of a single Java program that runs on the same or different machines. The IBIS registry is an additional program that runs on one machine. Its purpose is to simply register the location of each machine and broadcast this information to the other instances, so that each one is aware of everybody else.
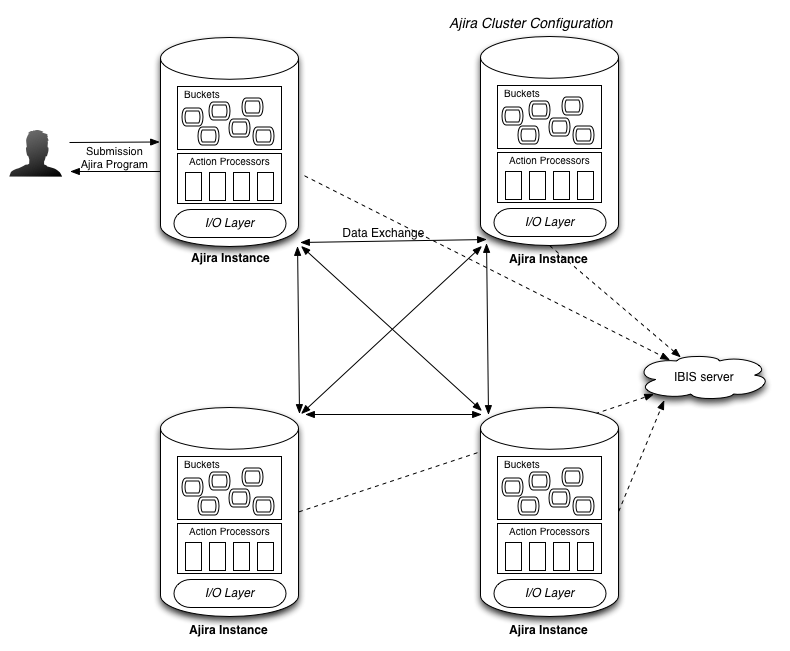
Figure 2: Overview of an Ajira Cluster.
An user submits an Ajira program to one node of this network, which will initiliaze the computation and makes sure the result is returned to the user.
There are several components within each Ajira instance that are quite important. The first is called I/O Layer and it is the layer that handles the communication between the framework and the physical data source from where the data is retrieved. More in particular, it exchanges tuples of data, which are the way data is represented in the framework. We discuss respectivily the I/O Layer and the tuples here and here.
Once the data is retrieved by the I/O layer, the framework starts feeding it the Ajira program, which consists on a sequence of actions that process the tuples in input. The execution of these actions happens in parallel, since the framework starts a number of concurrent threads to process the actions on multiple portions of the data. We will discuss the structure of actions, and the execution of such sequences here.
Finally, other important components of every Ajira instances are the buckets, which are responsible for temporary storing the data and send them through the network. We discuss them extensivily here.
I/O Layer
The I/O layer is responsible of returning an iterator tuples that should serve as input to the sequence of actions. This iterator is dependent to a query that the framework requests to the layer. Therefore, we can see the input layer as a sort of database, which returns a set of results (in the form of a sequential iterator) given a specific query in input.
For example, the standard FileLayer represents the layer if the Ajira program wants to read the input from files. In this case, an example of query that the framework could launch to the input layer could be the tuple (1,xxx), which is interpreted by the input layer as "Returns me the content of file xxx (this is the code for the operation '1') using the standard iterator."
Once it has receives this query query, the input layer returns an appropriate iterator of type TupleIterator, that contains the tuple that satify the query. Then, the framework reads each elements returned by the iterator, feeds these tuples to the first action of the sequence, and once the iterator is finished it releases it by returning it to the input layer.
The actions in one ajira action can read the tuples from an arbitrary number of iterators. For example, some actions could read the content of some files, while others could read data from a stream of data. Before the Ajira framework is started, we can set a default input layer, which will be used in case no input layer is specified. This operation is done using the code:
Ajira ajira = new Ajira();
Configuration conf = ajira.getConfiguration();
InputLayer.setDefaultInputLayerClass("inputLayerClass", conf);
The only difference between the default input layer and all the others is that for such input layer the framework calls an initialization method when it is loaded. This gives the possibility to the user to set up the I/O system before the computation can take place (this could become particular handy if our input layer was, for example, the interface to a relational database).
Now, let's discuss the APIs offered by the input layer. Basically, every input layer must be defined as a subclass of the abstract class InputLayer.
Each subclass must implement four methods:
- load(): This method is invoked once by the framework when the cluster is started. The frameworks calls it only for the default input layer.
- getIterator(Tuple tuple, ActionContext context): This method returns a tuple iterator given an input query (which is contained in a generic tuple). The structure and content of the query depends on the I/O layer. For example, a query for the FileLayer could be (1,"/file1.txt") while for another layer could have a completely different structure.
- releaseIterator(TupleIterator itr, ActionContext action): Once the tuple iterator is used, the framework releases it to the I/O layer, which can possibly reuse it or perform additional computation to clean up the itertor state.
- getLocations(Tuple tuple, ActionContext context): This method is invoked by the framework to know in which node the given query could be answered. In fact, some queries might be answered only on a specific node of the cluster. If this is the case, then the framework will first transfer the list of action to this node, and there request a tuple iterator. Note, that this method returns an object of type Location, which is used to indicate a location in the cluster. This object can return: (i) the ID of one node in the cluster (in the range from 0 to n, where n is the number of Ajira instances); (ii) -1, if this query should be executed on all the nodes; (iii) -2, if the query can be answered only on the local node.
This last method can be used to redirect the computation to some specific nodes. For this moment, it is possible to redirect either to another single node, or to replicate it on all the nodes. In both cases, the framework will take care of distributing the list of actions over the network and make sure that the program correctly terminates.
The iterator must be a subclass of TupleIterator. This abstract class requires the implementation of three methods: (i) isReady(), which returns true if the iterator can start returning tuples; (ii) next(), which returns whether there is a new tuple to be read; (iii) getTuple(Tuple tuple), to retrieve the content of the current tuple.
Tuples and Datatypes
In traditional MapReduce applications, data is expressed as a set of key/value pairs. In Ajira, we relax this constraint, and define the data as a set of generic tuples, of arbitrary type and length. For example, one tuple could contain three, or four elements, and the type of this elements can be changed at runtime. This allows us to represent the underlying data in a much more intuitive way, without using expensive and complex mechanisms to serialize complex data structures on key/value pairs.
More in particular, we simply require that each element of the tuple is an instance of the abstract class SimpleData. The framework already provides the implementation for many standard types, such as strings, integers, longs, boolean, etc. We report all the supported types in the table below:
| Type | Description |
|---|---|
| TInt | An Integer number. |
| TString | A String number. |
| TBoolean | A Boolean number. |
| TLong | A Long number. |
| TByte | A Byte number. |
| TDouble | A Double number. |
| TBag | A collection of tuples (used in the GroupBy action). |
| TIntArray | An array of integers. |
| TByteArray | An array of bytes. |
| TStringArray | An array of strings. |
| TLongArray | An array of longs. |
| TDoubleArray | An array of doubles. |
Notice that if your application needs to use a special type, then you can define it by creating as a subclass of SimpleData. However, in this case you need to register your data type before you start your architecture. This can be done by calling the static method DataProvider.get().addType("Your Typle".class).
Actions
The kernel of computation in an Ajira cluster is represented by the actions. As we described in the tutorial, an Ajira program is in its essence nothing but a sequence of actions.
In Ajira, each action must inherit the abstract class Action. The only method that you must implement is process(), which receives one tuple in input and produces zero or more tuples in output. This can be done using the method output() provided by the ActionOutput object.
When an action is added to a sequence, the framework gives us the possibility to customize the execution by adding some parameters. These parameters can be set by using the method setParam* of the class ActionConf. This method requests that we specify an parameter id next to the value to assign. The list of parameters IDs can be set overriding the method registerActionParameter() of Action. This method allows us to specify which parameters are allowed by invoking the method registerParameter() of ActionConf.
For example, consider the following code:
public final int PARAM1 = 0;
public final int PARAM2 = 1;
registerActionParameters(ActionConf conf) {
conf.registerParameter(PARAM1, "desc. param 1", null, true);
conf.registerParameter(PARAM2, "desc. param 2", 10, false);
}
With this code, we allow two parameters for our action, PARAM1 and PARAM2. The first has ID=0, while the second has ID=1. We require that the first parameter is always set (cannotBeNull=true), while the second assumes the default value of 10, unless it is specified.
Within the action, the actual value of the parameters can be retrieved using the methods getParam*(PARAM_ID). Normally these parameters are useful when the process starts or closes. To allow the user to customize the computation in these two phases, the framework invokes two methods of Action that can be overriden by the user. These are:
- startProcess(): This method is invoked once before the action starts to receive tuples in input through the process() method. You can use it to initialize your data structures.
- stopProcess(): Similarly, this method is invoked once after the action has received all the tuples in input. Notice that in this method you can still output some tuples. This can be useful in case you need to alert the following actions that the flow is finished.
You must keep in mind a very important principle when you are writing the code of your action: There is only one way to ensure a single global flow in the system, and we will describe it later when we discuss the buckets. In all the other cases, the same action can be concurrently executed multiple times on different parts of the input. Therefore, never make the assumption that there is only one process flow. The only assumption that you can make is that before and after any process() call there will be one startProcess(), and one stopProcess() call.
In fact, some actions can create multiple processing flows which execute the same sequence of actions on different data. This is done concurrently, since in each Ajira instance there are normally multiplw action processors that initialize the sequences of actions and coordinate the passing of tuples between the list of actions.
Furthermore, there can be cases where a static computational flow is not enough and new sequences must be created at runtime. In this case, the object ActionOutput in process() and stopProcess() allows the user to perform two useful operations: branching and splitting.
We first describe the branch operation. As an example, suppose we have a simple list of actions from A to E, as shown in the Figure below.
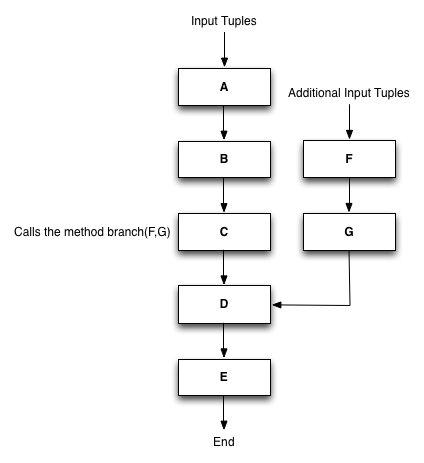
Figure 3: Branch operation.
During the action C, we might want to send more tuples to the following actions that come from a different computation than the current flow. In this case, action C can create a branch composed by the actions F, and G, and the tuples outputed by this new sequence will be send directly to the action D.
This operation can be particularly useful if we need to implement explorative operations, which are operations which complexity depends on the data that is being processed. Some examples could be the execution of data joins (i.e. we need to read both sides of the join only if there is data that satifies one of them), or the execution of rules in logic programming.
Branching can be implemented by the user in a very simple way: simply call the method branch(ActionSequence sequence) indicating which actions should be executed in the branch and the framework will take care to create the new sequence, assign its execution to a local or remote thread, and ensure that the flow is correctly handled.
However, notice one important aspect: branching cannot be used to change the destiny to the tuples produced by the current action. It can only be used to add more tuples that come from a different source (this is translated in one addition query to the input layer, and the usage of one more action processor to process the new actions).
If, during the execution of one action, we want that the tuples that are being produced are processed in a different way, then we can use the split operation. Once again, suppose as example that we have a simple sequence of actions from A to E as reported in the figure below.
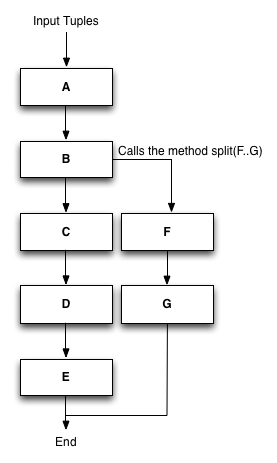
Figure 4: Split operation.
Here, the action C can create a split with the new actions F and G, and send the tuples that it produces through this channel rather than the default one. When the action creates a split, it can specify after how many actions the split can be reconnected to the main flow. This is useful if we want that only a limited number of operations is skipped, and the output of G is send as input to one action between D and E.